GO 语言 一、基本语法知识 1. Go语言的基本组成 先来看一段入门代码
package mainimport "fmt" func main () "Hello, PP" )
1.1 包声明 定义了包名。通常需要在源文件第一行指明文件属于哪个包。
package main 表示一个可独立执行的程序,每个工程都应包含一个名为main的包。
1.2 引入包 告诉编译器程序需要使用fmt包中的东东(函数、变量或其他元素)。
fmt包实现了格式化IO的函数
1.3 函数 func main () "Hello, PP" )
这是程序开始执行的函数。main()函数式每一个可执行程序必须包含的,通常在程序启动后立即执行。
1.4 变量 变量的声明和初始化
a.标准格式
var是关键字
使用 var ,虽然只指定了类型,但是 Go 会对其进行隐式初始化,比如 string 类型就初始化为空字符串,int 类型就初始化为0,float 就初始化为 0.0,bool类型就初始化为false,指针类型就初始化为 nil。
也可以在声明的同时初始化
go会对右边的值进行类型判断,因此我们也可以在声明时省去类型,简写为
内部变量(用在函数内部)和全局变量均适用
b.同时声明多个变量
var (int string float32
内部变量和全局变量均适用
c.短类型声明法
使用:=声明 变量,可以显式初始化。变量和常量通常都只能声明一次。也有例外,匿名变量可以多次声明。
只能用于函数内部
声明初始化多个变量
d.声明指针变量
go语言提供了new函数来声明指针变量
这将创建一个Type类型的匿名变量,初始化为Type类型的初始值(go语言默认),返回值为匿名变量地址,指针类型为&Type
package mainimport "fmt" func main () new (bool )"ptr address: " , ptr)"ptr value: " , *ptr)
输出
ptr address: 0xc000016088
可以看出,用new创建指针变量和用&创建指针变量能达到一样的效果,除了不需要使用具体的变量名。上面的代码用普通方法创建指针变量可以写为:
package mainimport "fmt" func main () var boolean bool "ptr address: " , ptr)"ptr value: " , *ptr)
匿名变量
称作占位符,或者空白标识符,用下划线_表示。它可以像其他标识符那样用于变量的声明或赋值(任何类型都可以赋值给它),但任何赋给这个标识符的值都将被抛弃,因此这些值不能在后续的代码中使用,也不可以使用这个标识符作为变量对其它变量进行赋值或运算。
特点:
1.不分配内存,不占用内存空间
2.可以多次声明
3.解决命名的烦恼
通常我们用匿名接收必须接收,但是又不会用到的值。
func GetData () (int , int ) return 100 , 200 func main ()
输出
2.变量的作用域 局部变量
在函数体内声明的,作用域只在函数体内。
局部变量不是一直存在的,它只在定义它的函数被调用后存在,函数调用结束后这个局部变量就会被销毁。
package mainimport ("fmt" func main () 3 var b int = 4 "a = %d, b = %d, c = %d\n" , a, b, c)
输出:
全局变量
在函数体外声明的变量。全局变量的声明必须以关键字var开头,如果想要在外部包中使用全局变量的首字母必须大写。
package mainimport "fmt" var c int func main () var a, b int 3 4 "a = %d, b = %d, c = %d\n" , a, b, c)
输出
Go中全局变量和局部变量名称可以相同,但函数体内的局部变量会被优先考虑
package mainimport "fmt" var a int = 6 func main () var a int = 3 "a = %d\n" , a)
输出
3. 数据类型 3.1 布尔型 取值只能是true或者false
3.2 数字类型 整型int 和浮点型float32 和float64 ,同时支持复数 运算
const e = .3652 const f = 1. const Avogadro = 6.02214129e23 const Planck = 6.62606957e-34
计算机中,复数是由两个浮点数表示的,其中一个表示实部(real),一个表示虚部(imag)。
Go语言中复数的类型有两种,分别是 complex128(64 位实数和虚数)和 complex64(32 位实数和虚数),其中 complex128 为复数的默认类型。
声明复数的语法格式
var z complex128 = complex (x, y)complex (x, y)real (z)imag (z)
复数也可以用==和!=进行相等比较,只有两个复数的实部和虚部都相等的时候它们才是相等的。
3.3 字符类型byte、rune及字符串类型 (a)byte
占用一个字节,8个bit位,表示ASCII表中的一个字符
(b)rune
占用4个字节,32个bit位,表示一个Unicode字符
import ("fmt" "unsafe" func main () var a byte = 'A' var b rune = 'B' "a 占用 %d 个字节数\nb 占用 %d 个字节数" , unsafe.Sizeof(a), unsafe.Sizeof(b))
输出
可以看出rune占用的字节数更多,表示的字符范围也比byte更广。
有一点需要注意,与python不同的是,Go中的单引号和双引号并不等价。单引号用来表示字符,双引号用来表示字符串,混用则会导致编译器报错。
(c)字符串
也就是string类型,它的实质就是一堆字符拼接起来的数组。
在初始化字符串时,可以用双引号“”或者反引号。大多情况下,二者并没有区别,但如果你的字符串中有转义字符\ ,这里就要注意了,它们是有区别的。
使用反引号包裹的字符串,会忽略里面的转义。
比如表示 \r\n 这个 字符串,使用双引号是这样写的,这种叫解释型表示法
var mystr01 string = "\\r\\n"
而使用反引号,就方便多了,这种叫原生型表示法
var mystr02 string = `\r\n`
当你想打印解释型字符串的原型时,可以使用fmt 的 %q 来还原一下。
import ("fmt" func main () var mystr01 string = `\r\n` `\r\n` )"的解释型字符串是: %q" , mystr01)
输出如下
在反引号包裹的字符串中,无法用\n表示换行,那么可以直接回车进行换行
import ("fmt" func main () var mystr string = `hello weipp`
输出
字符串的常见操作 1.拼接字符串 + 两个字符串 s1 和 s2 可以通过 s := s1 + s2 拼接在一起。将 s2 追加到 s1 尾部并生成一个新的字符串 s。
也可以使用“+=”来对字符串进行拼接:
s := "hel" + "lo," "world!"
2.字符串比较 func Compare (a, b string ) int func EqualFold (s, t string ) bool
示例:
a := "hello weipp" "hello world" "GO" , "go" )) "壹" , "一" ))
3.是否存在某个字符或子串 有三个函数能实现相关功能
func Contains (s, substr string ) bool func ContainsAny (s, chars string ) bool func ContainsRune (s string , r rune ) bool
示例:
"abcd" , "ab" )) "abcd" , "e" )) "abcd" , "a & c" )) "ab cd" , "s g" )) "abcd" , "" )) "" , "" )) "abcd" , 'a' ))
查看源码可以发现这些函数都是调用了Index函数,Index函数通过子串(字符)与原串的索引进行比较,返回-1,0,1三个数。将这三个数与0比较,返回true或false
func Contains (s, substr string ) bool return Index(s, substr) >= 0 func ContainsAny (s, chars string ) bool return IndexAny(s, chars) >= 0 func ContainsRune (s string , r rune ) bool return IndexRune(s, r) >= 0
4.大小写转换 func ToLower (s string ) string func ToLowerSpecial (c unicode.SpecialCase, s string ) string func ToUpper (s string ) string func ToUpperSpecial (c unicode.SpecialCase, s string ) string
大小写转换包含了 4 个相关函数,ToLower,ToUpper 用于大小写转换。ToLowerSpecial,ToUpperSpecial 可以转换特殊字符的大小写。 请看例子:
fmt.Println(strings.ToUpper("hello world" ))"ā á ǎ à" ))"一" ))"hello world" ))"örnek iş" ))"örnek iş" ))
3.4 派生类型 (a) 指针类型(Pointer) 指针声明格式
var-type 为指针类型,var_name 为指针变量名,* 号用于指定变量是作为一个指针。看下示例:
var ip *int var fp *float32 var sp *string
指针创建
1 new (int )10
打印指针指向的内存地址
"%p" , ptr)
Go空指针
当一个指针被定义后没有分配到任何变量时,它的值为 nil。
nil 指针也称为空指针。
nil在概念上和其它语言的null、None、nil、NULL一样,都指代零值或空值。
var ptr1 *int "ptr1 的值为 : %x\n" , ptr1 )new (int )"ptr2 的值为 : %x\n" , ptr2)
输出:
ptr1 的值为 : 0
奇怪的事情的发生了,第一种声明方式是空指针,而第二种声明方式显然不是。其实用new方法创建指针的时候,返回值是type初始值的地址,在此例中int的初始值为0,因此返回0值的地址。
可以简单验证下:
ptr2 := new (int )"ptr2 的值为 : %x\n" , ptr2)"ptr2 指向的值为 : %x\n" , *ptr2)
(b) 数组类型 数组是具有相同唯一类型的一组长度固定的数据项序列,这种类型可以是任意的原始类型例如整型、字符串或者自定义类型。
数组声明格式
var variable_name [SIZE] variable_type
看下示例:
初始化
var ages = [5 ]int {1 ,2 ,3 ,4 ,5 }5 ]int {1 ,2 ,3 ,4 ,5 }var ages = [...]int {1 ,2 ,3 ,4 ,5 }int {1 ,2 ,3 ,4 ,5 }5 ]int {1 :2 ,3 :4 }
[3]int 和 [4]int 虽然都是数组,但他们却是不同的类型,使用 fmt 的 %T 可以查到。
import ("fmt" func main () int {1 , 2 , 3 }int {1 , 2 , 3 , 4 }"%d 的类型是: %T\n" , arr01, arr01)"%d 的类型是: %T" , arr02, arr02)
输出
[1 2 3] 的类型是: [3 ]int [1 2 3 4] 的类型是: [4 ]int
(c) 切片类型(slice) Go 语言切片是对数组的抽象。
事实上切片是一种引用类型,这个片段可以是一整个数组,也可以是数组中的一段,另外,这是左闭右开的区间。
Go 数组的长度不可改变,在特定场景中这样的集合就不太适用,Go 中提供了一种灵活,功能强悍的内置类型切片(“动态数组”),与数组相比切片的长度是不固定的,可以追加元素,在追加时可能使切片的容量增大。很像python中的list。
切片的声明和初始化
1.对数组进行片段截取
myarr := [5 ]int {1 , 2 , 3 , 4 , 5 }"myarr 的长度为:%d,容量为:%d\n" , len (myarr), cap (myarr))1 :3 ]"mysli1 的长度为:%d,容量为:%d\n" , len (mysli1), cap (mysli1))1 :3 :4 ]"mysli2 的长度为:%d,容量为:%d\n" , len (mysli2), cap (mysli2))
输出 说明切片的第三个数,影响的只是切片的容量,而不会影响长度
myarr 的长度为:5,容量为:5
可以发现mysli1和mysli2的打印结果是一样的。那mysli1 := myarr[1:3]和mysli2 := myarr[1:3:4]的区别在哪呢
在切片时,若不指定第三个数,那么切片终止索引会一直到原数组的最后一个数。而如果指定了第三个数,那么切片终止索引只会到原数组的该索引值。
好绕是不是,举个例子,mysil := myarr[x:y:z]意思是我将myarr[x,z)的所有值给切片mysil,切片mysil的容量大小为(z-x)。但我打印mysil时,只打印myarr[x,y),切片mysil的长度大小为(y-x)。
代码验证一下
var numbers4 = [...]int {1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 }4 :6 :8 ]"myslice为 %d,其容量为:%d,其长度为: %d\n" , myslice, cap (myslice), len (myslice))cap (myslice)]"myslice的第四个元素为: %d" , myslice[3 ])
输出
myslice为 [5 6],其容量为:4,其长度为 : 2myslice的第四个元素为 : 8
2.仅声明
var strList []string var numList []int var numListEmpty = []int {}
3.make函数构造
make( []Type, size, cap )
我们只需要提供切片所需的三个要素,类型type,长度size和容量cap。
a := make ([]int , 2 )make ([]int , 2 , 10 )len (a), len (b))cap (a), cap (b))
4.用:=直接声明
a := []int {4 :2 }len (a), cap (a))
注意在声明时数组和切片的区别:
数组一定要指明长度,如果没有确切数字也必须要写上...
arr := [5]int{1,2,3,4,5}
arr := [...]int{1,2,3,4,5}
切片长度不固定,不需要指明长度
sli := []int{1,2,3,4,5}
由于切片是引用类型,所以你不对它进行赋值的话,它的零值(默认值)是 nil
var myarr []int nil )
数组和切片都是可以容纳若干类型相同的元素的容器。
不同点在于,数组容器大小固定,而切片作为引用类型,大小不固定,可以在里面随意添加删除元素。
myarr := []int {1 }append (myarr, 2 )append (myarr, 3 , 4 )append (myarr, []int {7 , 8 }...)append ([]int {0 }, myarr...)append (myarr[:5 ], append ([]int {5 ,6 }, myarr[5 :]...)...)
输出 如下
(d) Channel 类型 它是一个数据管道,可以往里面写数据,从里面读数据。
channel 遵循先进先出原则。
写入,读出数据都会加锁,因此线程是安全的。
channel 可以分为 3 种类型:
只读 channel,单向 channel
只写 channel,单向 channel
可读可写 channel
channel 还可按是否带有缓冲区分为:
带缓冲区的 channel,定义了缓冲区大小,可以存储多个数据
不带缓冲区的 channel,只能存一个数据,并且只有当该数据被取出才能存下一个数据
声明和初始化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 var readOnlyChan <-chan int var writeOnlyChan chan <- int var ch chan int make (<-chan int , 2 ) make (<-chan int ) make (chan <- int , 4 ) make (chan <- int ) make (chan int , 10 ) 20
基本操作方式
读 <-ch
i := <-ch
写 ch<-
ch <- 20
关闭 close(ch)
close(ch)
带缓冲和不带缓冲的 channel
不带缓冲区 channel
看个例子吧
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 package mainimport "fmt" func main () make (chan int ) go unbufferChan(ch)for i := 0 ; i < 10 ; i++ {"receive " , <-ch) func unbufferChan (ch chan int ) for i := 0 ; i < 10 ; i++ {"send " , i)
输出:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 send 0 1 0 1 2 3 2 3 4 5 4 5 6 7 6 7 8 9 8 9
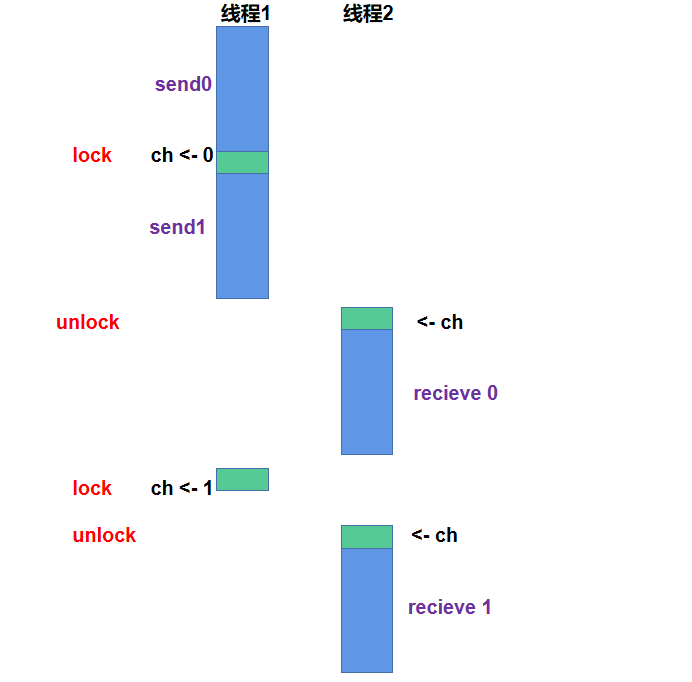
对于不带缓冲区的channel,只能存一个数据。当读入一个数据后,会加锁,当这个数据被读出时,才会解锁。一个数据的读入和读出一一对应,线程是安全的。那么输出结果为什么是两个send两个receive呢?
我画了一张图讲下我的理解:
首先运行线程1:打印出send 0,将0送入channel,此时lock,之后打印出send 1。再往下无法继续读入,需要读出数据,因此切换至线程2:读出0,打印receive 0。这里解释下为什么线程2读出0后没有直接切换到线程1读入1:因为线程切换需要时间,在准备切换时,已经接到了打印receive 0的命令,此时先打印receive 0,之后再切换到线程1。线程1:将1送入channel,此时函数在改变for循环变量i,这段时间线程2抢到进程。线程2:读出1,打印receive 1。
带缓冲区 channel
package mainimport ("fmt" func main () make (chan string , 3 )"tom" "jimmy" "cate"
输出
判断 channel 是否关闭
ok 为 true,读到数据,管道没有关闭
ok 为 false,管道已关闭,没有数据可读
浅浅试一下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 package mainimport ("fmt" func main () make (chan int )go test(ch)for {if v, ok := <-ch; ok {"get val: " , v, ok)else {break func test (ch chan int ) for i := 0 ; i < 5 ; i++ {close (ch)
输出
get val: 0 true
读已经关闭的 channel 会读到零值,如果不确定 channel 是否关闭,可以用这种方法来检测。
遍历channel
通常用for range遍历channel,,如果发送者没有关闭 channel 或在 range 之后关闭,都会导致 deadlock(死锁)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 package mainimport "fmt" func main () make (chan int )go func () for i := 0 ; i < 10 ; i++ {for val := range ch {close (ch)
输出
0 1 2 3 4 5 6 7 8 9 all goroutines are asleep - deadlock!
把 close(ch) 移到 go func(){}() 里进行修改,像这样:
go func () for i := 0 ; i < 10 ; i++ {close (ch)
select 使用
Go中的select和channel配合使用,通过select可以监听多个channel的I/O读写事件,当 IO操作发生时,触发相应的动作。
基本用法:
select {case <- chan1:case chan2 <- 1 :default :
看个例子
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 package mainimport "fmt" func fibonacci (ch, quit chan int ) 0 , 1 for {select {case ch <- x:case <-quit:"quit" )return func main () make (chan int )make (chan int )go func () for i := 0 ; i < 10 ; i++ {0
输出
0
(e) 函数类型 函数是基本的代码块,负责执行不同的功能。
Go 语言至少需要有个 main() 函数。
函数声明告诉了编译器函数的名称,返回类型,和参数
函数定义
func function_name ( [parameter list] ) [return_types ]
func:函数由 func 开始声明
function_name:函数名称,参数列表和返回值类型构成了函数签名。
parameter list:参数列表
return_types:返回类型,函数返回一列值。
函数体:函数定义的代码集合。
函数调用实例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 package mainimport "fmt" func main () var a int = 100 var b int = 200 var ret int "最大值是 : %d\n" , ret )func max (num1, num2 int ) int var result int if (num1 > num2) {else {return result
输出
值传递&引用传递
值传递:值传递是指在调用函数时将实际参数复制一份传递到函数中,这样在函数中如果对参数进行修改,将不会影响到实际参数。
引用传递:引用传递是指在调用函数时将实际参数的地址传递到函数中,那么在函数中对参数所进行的修改,将影响到实际参数。
(f) 结构化类型(struct) 在结构体中我们可以为不同项定义不同的数据类型。
定义结构体
type struct_variable_type struct {
结构体变量声明
variable_name := structure_variable_type {value1, value2...valuen}
看个例子
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 package mainimport "fmt" type Blogs struct {string string string int func main () "Go入门与实战" , "weipp" , "23/8/2022" , 429761 })"Go入门与实战" , author: "weipp" , date: "23/8/2022" , id: 429761 })"Go入门与实战" , author: "weipp" })
输出
{Go入门与实战 weipp 23 /8/ 2022 429761 }23 /8/ 2022 429761 }0 }
访问结构体成员
var blog1 Blogs"Go入门与实战" "weipp"
var blog2_ptr *Blogsvar blog2 Blogs"Go入门与实战" "weipp"
(g) 接口类型(interface) 接口把所有的具有共性的方法定义在一起,其他函数想要使用这些方法时调用接口即可。降低代码的耦合性。
type interface_name interface {func (struct_name_variable struct_name) method_name1 () [return_type ]func (struct_name_variable struct_name) method_namen () [return_type ]
示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 package mainimport ("fmt" type Phone interface {type NokiaPhone struct {func (nokiaPhone NokiaPhone) call () "I am Nokia, I can call you!" )type IPhone struct {func (iPhone IPhone) call () "I am iPhone, I can call you!" )func main () var phone Phonenew (NokiaPhone)new (IPhone)
输出结果:
I am Nokia, I can call you!I am iPhone, I can call you!
(h) Map 类型
map是无序的键值对集合,很像python中的字典,是key-value结构。因为是map是用hash表实现的,所以每次打印出来的map都不一样,而且只能通过key获取。
map是一种引用类型,长度不固定,和slice一样
map的值可以通过重新赋值直接修改
声明和初始化
声明格式
var mapName map[key] value
key为键类型,value为值类型
其中value既可以是基本数据类型,也可以为自定义数据类型
var numbers map [string ] int var myMap map [string ] personInfotype personInfo struct {string string string
初始化
:=直接创建
rating := map [string ] float32 {"C" :5 , "Go" :4.5 , "Python" :4.5 , "C++" :2 }map [string ] personInfo{"1234" : personInfo{"1" , "Jack" , "Room 101,..." },}
make方法构造map
mapName := make(map[key] value)
numbers := make (map [string ] int )"one" ] = 1
元素查找
这里的查找功能很巧妙,不需要像别的语言那样检查取到的值是否为空,而是返回两个参数。判断第二个参数ok的值0/1即可。
value, ok := numbers["one" ]if ok{
元素修改
非常简单,定位需要修改的key-value对,直接改变value即可
注意:map是引用类型,如果两个map同时指向一个对象,那么一个改变,另一个也相应改变。
numbersTest := numbers"one" ] = "111"
元素删除
可以使用Go的内置函数delete(),用于删除容器内的元素。
上面的代码将从myMap中删除键为“one”的键值对。如果“one”这个键不存在,那么这个调用将什么都不发生,也不会有什么副作用。但是如果传入的map变量的值是nil,该调用将导致程序抛出异常(panic)。
示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 package mainimport "fmt" type Blogs struct {string string string int func main () map [string ]int {"one" : 1 ,"two" : 2 ,"three" : 3 ,map [string ]Blogs{"blog1" : {"Day1" , "weipp" , "25/8" , 001 },"blog2" : {"Day2" , "weipp" , "26/8" , 002 },"blog3" : {"Day3" , "weipp" , "27/8" , 003 },"two" ])"blog1" ])"blog" ]if ok {"Found" )else {"Not found" )delete (numbers, "one" )
输出
map[one:1 three:3 two:2] 2 map[blog1: {Day1 weipp 25/8 1} blog2: {Day2 weipp 26/8 2} blog3: {Day3 weipp 27/8 3} ] {Day1 weipp 25/8 1} Not found map[three:3 two:2]
4.循环控制 4.1条件语句 if-else语句 基本格式
if 条件 1 {1 else if 条件 2 {2 else if 条件 ... {else {else
Go的编译器,对于{和}的位置要求十分严格,在编写代码的时候,else if或else和两边的花括号,必须在同一行,否则编译器报错。
另外需要注意的是,if后面的条件表达式必须严格返回布尔型的数据(0/1/nil均不行)
进阶用法
可以先运行一个表达式,再对条件进行判断(这样看起来是不是牛逼点)
例如
import "fmt" func main () if year := 2020 ;year >= 2000 {"现在进入二十一世纪" )
switch 语句 基本格式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 switch var0 {case val1:case val2:default :switch var0 {case val1,var2,var3:case val4:default :
switch语句从上到下执行,直到找到匹配。
默认情况下每个case最后都自带break,匹配成功后即跳出循环,不会向下执行。如果需要匹配后面的case,需要加上语句fallthrough
var year int = 2020 switch year {case 2020 :"Welcome class of 2020!" )case 2021 :"Welcome class of 2021!" )case 2022 :"Welcome class of 2022!" )
此时case必须是函数的合理返回值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 package mainimport "fmt" func main () var year int = 2020 switch Welcome(year) {case true :"Welcome class of 2020 and after new students!" )case false :"Welcome old students!" )func Welcome (year int ) bool return year >= 2020
此时相当于 if - elseif - else
score := 30 switch {case score >= 95 && score <= 100 :"优秀" )case score >= 80 :"良好" )case score >= 60 :"合格" )case score >= 0 :"不合格" )default :"输入有误..." )
switch 的 default 不论放在哪都是最后执行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 10 switch {default : {"default" )case a > 0 : {"a > 0" )case a >5 : {"a > 5" )10 switch {case a > 0 : {"a > 0" )case a >5 : {"a > 5" )default : {"default" )
写法1和写法2没有区别
select 语句 select是一种控制结构,类似于用于通信的switch语句。
select里面的所有case语句要求是对channel操作,无论是在channel中写入数据还是从channel中读出数据。
select随机执行一个可运行的case。如果没有 case 可运行,它将阻塞,直到有 case 可运行。
直接看例子
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 package mainimport ("fmt" func main () make (chan string , 1 )make (chan string , 1 )"hello" select {case msg1 := <-c1:"c1 received: " , msg1)case msg2 := <-c2:"c2 received: " , msg2)
在运行 select 时,会遍历所有(如果有机会的话)的 case 表达式,只要有一个信道有接收到数据,那么 select 就结束,所以输出如下
关于deadlock
如果有多个case可以运行,select会随机选出一个执行。其他不会执行。
如果没有一个case可以运行,则会运行default子句。但若没有写default子句,select将阻塞,直到某个通信可以运行。Go 不会重新对 channel 或值进行求值。若一直没有通信能够运行,select就会抛出deadlock错误。如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 package mainimport ("fmt" func main () make (chan string , 1 )make (chan string , 1 )select {case msg1 := <-c1:"c1 received: " , msg1)case msg2 := <-c2:"c2 received: " , msg2)
输出
fatal error : all goroutines are asleep - deadlock!1 [select ]:text /text .go:13 +0 xbbexit status 2
如何解决呢?来看一哈
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 make (chan string , 1 )make (chan string , 1 )select {case msg1 := <-c1:"c1 received: " , msg1)case msg2 := <-c2:"c2 received: " , msg2)default :make (chan string , 1 )make (chan string , 1 )"hello" select {case msg1 := <-c1:"c1 received: " , msg1)case msg2 := <-c2:"c2 received: " , msg2)
关于随机性和持续执行
select是随机选择case语句,有满足则执行并退出,否则将一直持续检测。随机选择是为了避免饥饿问题(这是网上一个xd说的,有些道理)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 package mainimport ("fmt" "time" )func Chann (ch chan int , stopCh chan bool ) for j := 0 ; j < 10 ; j++ {true }func main () make (chan int )0 stopCh := make (chan bool )go Chann(ch, stopCh)for {select {case c = <-ch:"Receive C" , c)case s := <-ch:"Receive S" , s)case _ = <-stopCh:goto end
输出
// 第一次输出0 1 2 // 第二次输出0 1 2
综上,select跟switch有相同点也有不同:
select 只能用于 channel 的操作(写入/读出/关闭),而 switch 则更通用一些,switch后面可以接函数、其他表达式或不接;
select 的 case 是随机的,而 switch 里的 case 是顺序执行;
goto 无条件跳转语句 goto后接一个标签,作用是告诉go程序下一步要执行哪里的代码
goto 用于 跳出多层循环 或者 跳到多层循环的指定层 很好用
easy example
goto flag"B" )"A" )
执行结果,并不会输出 B ,而只会输出 A
注意:goto语句与标签之间不能有变量声明,否则编译错误。
defer 延迟执行 未完待续…
参考