应用DCT实现对音频水印的添加和提取
关于数字水印
数字⽔印技术是⼀种信息隐藏技术。所谓⾳频数字⽔印算法就是将数字⽔印通过⽔印嵌⼊算法嵌⼊到⾳频⽂件中(如 .wav、.mp3、.avi 等),但对原⾳质没有影响。也就是说,嵌入前后的音频人耳无法识别。水印提取的过程与前面正相反,我们需要从嵌入水印的音频中完整的提取出水印。
同时,水印嵌入音频需要对攻击和其他类型的失真具有鲁棒性,以防止篡改和伪造。典型的攻击包括添加噪声、数据压缩、过滤、重采样、混响等。
DCT思想
DCT变换的全称是离散余弦变换(Discrete Cosine Transform),DCT是一个特殊的DFT,也就是说,DCT变换就是输入信号为实偶函数的DFT变换。
我的想法是通过DCT变换将音频从时域转换到频域,在频域中寻找引起整体改变最小的数据块,并将其用我们的水印进行覆盖。
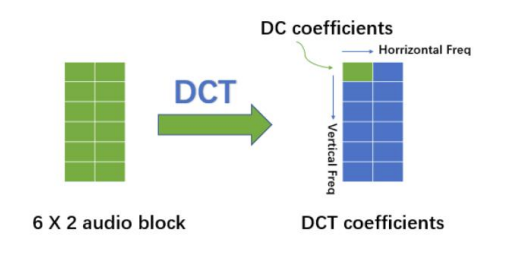
DCT和逆DCT的公式:
水平有限,只能不求甚解了😭
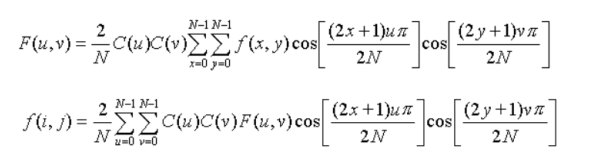
对音频添加音频水印
DCT水印算法思想
1:将原始音频统一转换为双声道数组(m行2列),对数组进行分块
2:假设我们得到n个这样的块
3:随机生成k秘钥。k的纬度和块纬度相同
4:水印的大小为w*h,因此水印中有feature=w*h个特征点
5:如果n≤feature,则无法嵌入水印
6:对水印中的每一个特征点,重复7-10:
7:计算第i个原始音频块的DCT,称其为dct block。
8:计算change[i] = k[i] × watermark[h][w]
9:将change[i]和当前dct block的最后一列相加,dct block[i, collum − 1]+ = change[i]
10:计算dct block的逆DCT并保存
11:得到嵌入水印的音频
关键代码思路
初始化对象
1
2
3
4
5
6
7
8
9
10
11
12
13
14def __init__(self, background, watermark, block_size, alpha):
b_h, b_w = background.shape[:2]
w_h, w_w = watermark.shape[:2]
assert w_h <= b_h / block_size, \
"\r\n请确保您的的水印音频尺寸 不大于 原有音频尺寸的1/{:}\r\nbackground尺寸{:}\r\nwatermark尺寸{:}".format(
block_size, background.shape, watermark.shape
)
# 块大小保存
self.block_size = block_size
self.block_size_y = b_w
# 水印强度控制
self.alpha = alpha
# 随机序列
self.k1 = np.random.randn(block_size)这里有一个强条件:水印音频是原有音频大小的1/n。否则水印块和原有块的映射关系被破坏,水印音频将无法完全插入到原有音频中。
分块&DCT变换
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18def dct_blk(self, background):
'''
对background进行分块,然后进行dct变换,得到dct变换后的矩阵
'''
background_dct_blocks_h = background.shape[0]//self.block_size
background_dct_blocks = np.zeros(shape=(
(background_dct_blocks_h,
self.block_size, background.shape[1])
))
# 前2个维度用来遍历所有block,后2个维度用来存储每个block的DCT变换的值
# 垂直方向分成background_dct_blocks_h个块
h_data = np.vsplit(background, background_dct_blocks_h)
for h in range(background_dct_blocks_h):
a_block = h_data[h]
# dct变换
background_dct_blocks[h, ...] = dct(a_block, type=3, norm="ortho")
return background_dct_blocks水印嵌入
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18def dct_embed(self, dct_data, watermark):
"""_summary_
嵌入水印到original audio的dct系数中
Args:
dct_data (_type_): original audio的dct系数
watermark (_type_): 音频数组
"""
print("--------dct_embed start-----------------")
temp = watermark.flatten()
result = dct_data.copy()
for h in range(watermark.shape[0]):
for w in range(watermark.shape[1]):
# 查询块(h,w)并遍历对应块的最后一列(影响最小的部分),进行修改
for i in range(self.block_size):
result[h, i, self.block_size_y-1] = dct_data[h,
i, self.block_size_y-1]+self.alpha*watermark[h][w]
print("--------dct_embed end-----------------")
return resultIDCT(DCT逆变换)
1
2
3
4
5
6
7
8
9
10
11
12
13
14def idct_embed(self, dct_data):
'''
进行对dct矩阵进行idct变换,完成从频域到空域的变换
'''
print("--------idct_embed start-----------------")
row = None
result = None
h = dct_data.shape[0]
for i in range(h):
print("--------Round:", i, "-----------------")
block = idct(dct_data[i, ...], type=3, norm="ortho")
result = block if i == 0 else np.vstack((result, block))
print("--------idct_embed end-----------------")
return result水印提取
在每一个块中,遍历对应的加密区域(每个块最后一列),进行加密的逆操作,得到提取出的水印。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18def dct_extract(self, synthesis, watermark_size, background):
"""
从嵌入水印的音频中提取水印
:param synthesis: 嵌入水印的空域音频
:param watermark_size: 水印大小
:return: 提取的空域水印
"""
w_h, w_w = watermark_size
recover_watermark = np.zeros(shape=watermark_size)
synthesis_dct_blocks = self.dct_blk(background=synthesis)
background_dct_blocks = self.dct_blk(background=background)
p = np.zeros(self.block_size)
for h in range(w_h):
for w in range(w_w):
for k in range(self.block_size):
recover_watermark[h, w] = (
synthesis_dct_blocks[h, k, self.block_size_y-1] - background_dct_blocks[h, k, self.block_size_y-1])/self.alpha
return recover_watermark绘制频谱图像
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20def draw_time(path, filename):
f = wave.open(path, 'rb')
params = f.getparams()
params = f.getparams()
# 通道数、采样字节数、采样率、采样帧数
nchannels, sampwidth, framerate, nframes = params[:4]
voiceStrData = f.readframes(nframes)
waveData = np.fromstring(voiceStrData, dtype=np.short) # 将原始字符数据转换为整数
# 音频数据归一化
waveData = waveData * 1.0/max(abs(waveData))
# 将音频信号规整乘每行一路通道信号的格式,即该矩阵一行为一个通道的采样点,共nchannels行
waveData = np.reshape(waveData, [nframes, nchannels]).T # .T 表示转置
f.close()
time = np.arange(0, nframes)*(1.0/framerate)
plt.plot(time, waveData[0, :], c='b')
plt.xlabel('time')
plt.ylabel('am')
plt.savefig('./%s.jpg' % filename)
plt.show()主函数
两个if:
if((np.shape(data_bg)[0] % block_size) != 0)如果数组大小无法平均分块,也就是说数组大小不是块的大小的整数倍,给数组后面加适当的零,使其变成块大小的整数倍
if(data_bg.ndim == 1)声道有单声道和立体声之分,单声道振幅数据为n*1矩阵点,立体声为n*2矩阵点
在单声道和双声道的处理上有所不同,要加特判
当音频为单声道时,相当于右耳或左耳其中一个通道是静音的,因此这里做的处理是将
n*1矩阵点->n*2矩阵点,即在数组后面加一列0(我的理解)。还有一种处理是将左右耳的通道变为一样的,即在数组后面加一列原数组。(这是另一种想法,我只尝试了前者)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51if __name__ == "__main__":
alpha = 0.1
block_size = 4
# 1.数据读取
samplerate_wm, data_wm = wavfile.read("piano_3s.wav")
samplerate_bg, data_bg = wavfile.read("buddy_19s.wav")
#若无法平均分块,也就是说数组大小不是块的大小的整数倍,给数组加一列0,使其变成块大小的整数倍
if((np.shape(data_bg)[0] % block_size) != 0):
data_bg = np.r_[data_bg, np.zeros(
block_size-(np.shape(data_bg)[0] % block_size))]
#将单声道音频转为双声道,方便统一处理
if(data_bg.ndim == 1):
a = np.array(np.zeros(data_bg.shape[0])).T
data_bg = np.c_[np.array([data_bg]).T, a]
print(np.shape(data_wm), np.shape(data_bg))
# 2.分块&dct
dct_embed = DCT_Embed(background=data_bg, watermark=data_wm,
block_size=block_size, alpha=alpha)
background_dct_blocks = dct_embed.dct_blk(background=data_bg)
# print(np.shape(background_dct_blocks))
# 3.嵌入水印到频域
embed_wm_blocks = dct_embed.dct_embed(
dct_data=background_dct_blocks, watermark=data_wm)
# 4.idct 从频域变换到时域
synthesis = dct_embed.idct_embed(dct_data=embed_wm_blocks)
data = normalizeForWav(synthesis)
wavfile.write("piano_dct.wav", samplerate_bg, data)
draw_time("piano_3s.wav","piano_3s")
draw_time("buddy_19s.wav","buddy_19s")
draw_time("piano_dct.wav","piano_dct")
# 5.提取水印
samplerate_syn, data_syn = wavfile.read("bunny_compress.wav")
if((np.shape(data_syn)[0] % block_size) != 0):
data_syn = np.r_[data_syn, np.zeros(
block_size-(np.shape(data_syn)[0] % block_size))]
if(data_syn.ndim == 1):
a = np.array(np.zeros(data_syn.shape[0])).T
data_syn = np.c_[np.array([data_syn]).T, a]
print(np.shape(data_syn))
extract_watermark = dct_embed.dct_extract(
synthesis=data_syn, watermark_size=data_wm.shape, background=data_bg)
data = normalizeForWav(extract_watermark)
wavfile.write("compress_ext.wav", samplerate_wm, data)
draw_time("piano_3s.wav", "piano_3s")
draw_time("compress_ext.wav", "compress_ext")
def normalizeForWav(data):
return np.int16(data.real)
结果展示
是时候展示真正的实力了!
- 原始音频
- 水印音频
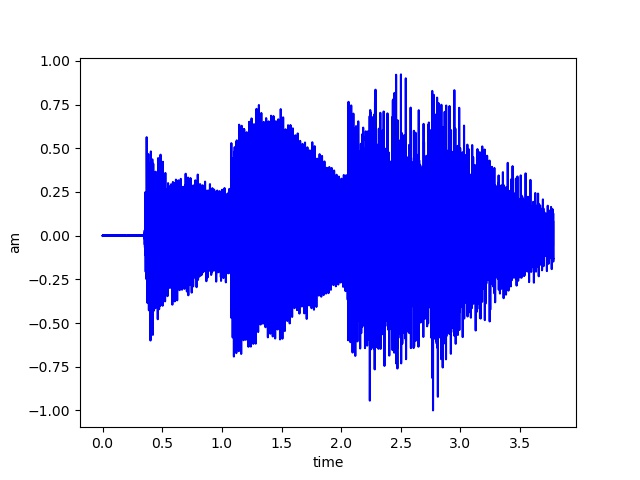
- 嵌入水印的音频
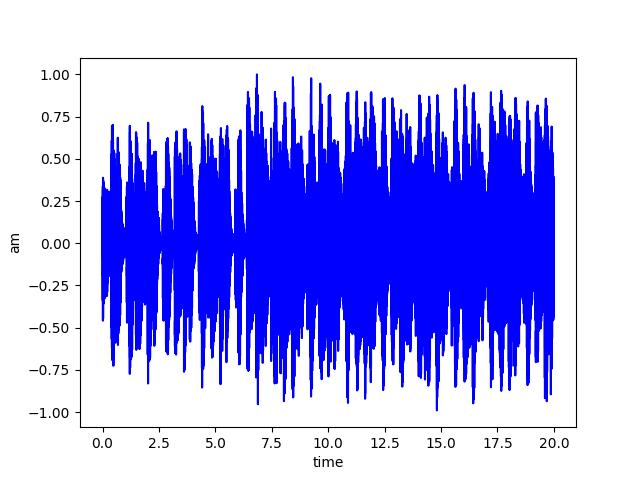
- 提取出的水印音频
结果分析
经过图像比对和相关性分析,可以看出提取出的水印和原水印还是有一些差别的。主要原因是将.wav格式的音频转为数组的时候,是int型数组。而在做DCT,IDCT变换后,数组变为float型。最后为了符合.wav格式,需要把float型强制转换为int型,这导致部分精度丢失。😭
对音频添加图像水印
跟前面的DCT算法思想类似,不同的就是将图片作为水印插入到音频中。与音频水印转换为的数组(m*2)不同,图片水印转换为的数组更大(m*n)。图片的像素点可以进行二值归一化,1表示黑色像素,0表示白色像素。
分块&DCT变换&水印嵌入
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31def dct_embed(audio0,leng,img):
numFrames = math.ceil(audio0.shape[0] / leng)
frames = list()
for i in range(numFrames):
frames.append(audio0[i * leng: (i * leng) + leng])
ary_frames=np.asarray(frames)
DCTCoeffs = np.copy(ary_frames)
for i in range(ary_frames.shape[0]):
DCTCoeffs[i] = DCT(ary_frames[i])
width, height = img.size
for i in range(len(DCTCoeffs)):
if i == 0:
audio = DCTCoeffs[i]
else:
audio = np.concatenate((audio, DCTCoeffs[i]), axis=0)
embedded = audio.copy()
# Embedding width and heigth
embedded[0][-1] = width
embedded[1][-1] = height
# Embedding watermark
for i in range(width):
for j in range(height):
value = img.getpixel(xy=(i, j))
value = 1 if value == 255 else 0
x = i * height + j
embedded[x + 32][0] = setLastBit(embedded[x + 32][0], value)
return embeddedIDCT变换
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17def idct_embed(audio,leng):
numFrames = math.ceil(audio.shape[0] / leng)
frames = list()
for i in range(numFrames):
frames.append(audio[i * leng: (i * leng) + leng])
ary_frames = np.asarray(frames)
iDCTCoeffs = np.copy(ary_frames)
for i in range(ary_frames.shape[0]):
iDCTCoeffs[i] = iDCT(ary_frames[i])
for i in range(len(iDCTCoeffs)):
if i == 0:
synthesis = iDCTCoeffs[i]
else:
synthesis = np.concatenate((synthesis, iDCTCoeffs[i]), axis=0)
return synthesis水印提取
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28def dct_extract(audio,leng):
numFrames = math.ceil(audio.shape[0] / leng)
frames = list()
for i in range(numFrames):
frames.append(audio[i * leng: (i * leng) + leng])
ary_frames = np.asarray(frames)
DCTCoeffs = np.copy(ary_frames)
for i in range(ary_frames.shape[0]):
DCTCoeffs[i] = DCT(ary_frames[i])
for i in range(len(DCTCoeffs)):
if i == 0:
audio = DCTCoeffs[i]
else:
audio = np.concatenate((audio, DCTCoeffs[i]), axis=0)
width, heigth = (112, 112) # sizeExtraction(joinAudio)
image = Image.new("1", (width, heigth))
# Embedding watermark
# Extraction watermark
for i in range(width):
for j in range(heigth):
x = i * heigth + j
value = getLastBit(audio[x + 32][0])
image.putpixel(xy=(i, j), value=value)
return image主函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43if __name__ == '__main__':
root = ".."
# 0. 超参数设置
length_frame = 4 # 每段长度
# 1. 数据读取
# watermak
img = Image.open("lock.png")
img = img.convert(mode="1",dither=0)
samplerate, data = wavfile.read("test.wav")
# print(data)
# print((np.asarray(data)).shape)
# 2. 嵌入水印图像
embed_watermak_audio = dct_embed(audio0=data,leng=length_frame,img=img) # 在dct块中嵌入水印图像
# 3. 将图像转换为空域形式
synthesis = idct_embed(audio=embed_watermak_audio,leng=length_frame) # idct变换得到空域图像
# print(synthesis)
# print((np.asarray(synthesis)).shape)
wavfile.write("Output.wav", samplerate, synthesis)
# 4. 提取水印
extract_watermark = dct_extract(audio=synthesis, leng=length_frame)
extract_watermark = extract_watermark.convert('RGBA')
# extract_watermark.show()
images = [img, extract_watermark]
titles = ["Watermark", "Extract_Watermark"]
for i in range(2):
plt.subplot(1, 2, i + 1)
if i % 2:
plt.imshow(images[i], cmap=plt.cm.gray)
else:
plt.imshow(images[i])
plt.title(titles[i])
plt.axis("off")
plt.show()
show_wav("test.wav")
show_wav("Output.wav")
结果展示
- 原始音频
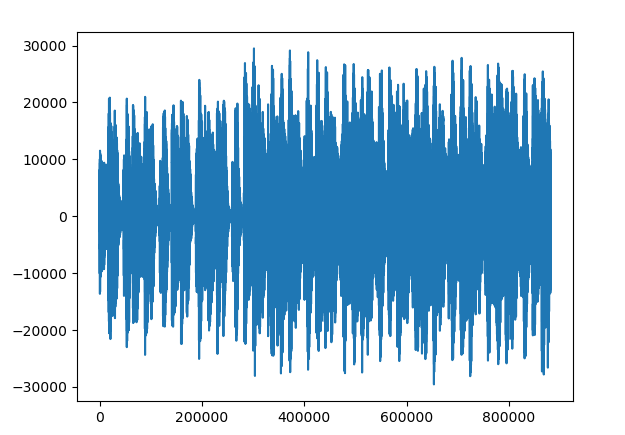
- 嵌入水印的音频
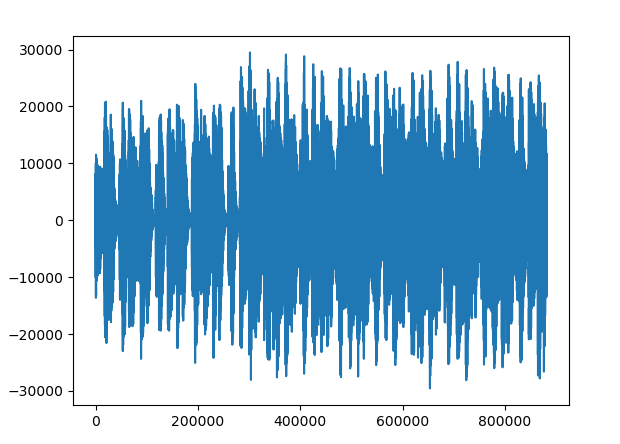
- 水印(肉眼看确实差点意思)
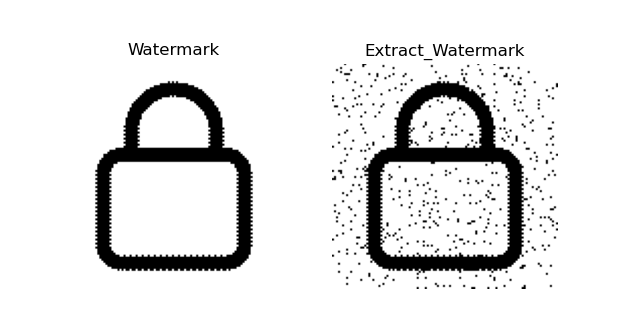
结果分析
同上,DCT,IDCT前后转换数据精度丢失的问题。
就这样吧
具体代码实现在这里
DCT-AUDIO DCT-IMAGE