关系三重提取的新框架
CASREL模型的分析
在做知识图谱的工作时,我们面临的首要问题是对一段语料进行实体识别(NER)和关系抽取(RE)。
啥?知识图谱是啥?
A knowledge graph, also known as a semantic network, represents a network of real-world entities—i.e. objects, events, situations, or concepts—and illustrates the relationship between them. This information is usually stored in a graph database and visualized as a graph structure, prompting the term knowledge “graph.”
简而言之,我们现实生活中的一切都可以用三元组(主语,关系,宾语)表示,抽象到图的数据结构中,圈圈代表主语和宾语,连接圈圈的箭头表示关系。
知识图谱的关键成分是关系事实,其中大部分由两个实体组成,由语义关系连接。 这些事实是以(主语,关系,宾语)或(s,r,o)的形式,称为关系三元组。
在之前的做法中,针对关系提取最早的做法是管道方法。它首先识别句子中的所有实体,然后对每个实体对进行关系分类。这种方法往往会受到错误传播问题的影响,因为早期阶段的错误无法在早期阶段得到纠正。
为了解决这个问题,后续大牛们提出了实体和关系的联合学习,其中有基于特征的模型以及神经网络模型。但是现有方法不能有效处理一个句子包含多个关系三元组的情况。
而且这些提取重叠三元组的工作仍有很多不足之处。
我们来看看当有多个三元组时,可能会出现的问题:
Normal:华科学生wpy邀请腾讯老板马化腾上模电课
关系三元组:(wpy,就读于,华科),(马化腾,CEO,腾讯)
EPO:姜文在他导演的让子弹飞中出演张麻子
关系三元组:(姜文,出演,让子弹飞),(姜文,导演,让子弹飞)
SEO:我出生在河南,郑州
关系三元组:(我,出生地,河南),(我,出生地,郑州),(郑州,是…省会,河南)
EPO:EntityPairOverlap
SEO:SingleEntityOverlap overlapping patterns.
面对上面的三元组重叠问题,现有方法都不能很好的解决。
具体来说,它们都将关系视为分配给实体对的离散标签。这个公式使关系分类成为一个困难的机器学习问题。首先,类分布高度不平衡。在所有提取的实体对中,大多数都没有形成有效的关系,产生了太多的反面例子。其次,当同一实体参与多个有效关系(重叠三元组)时,分类器可能会混淆。如果没有足够的训练样本,分类器很难分辨出实体参与了哪个关系。因此,提取的三元组是通常不完整和不准确。
这就体现出来CASREL牛逼的地方了,别人不能解决的,他行啊。
设计思路
该框架的核心是全新的观点,即我们可以将关系建模为将主体映射到对象的函数,而不是将关系视为实体对上的离散标签。这完全颠覆了以往的离散思想,而是把关系作为函数进行训练。更准确地说,我们不是学习关系分类器 f(s, o) → r,而是学习关系特定标记器 fr(s) → o,每个标记器都识别特定关系下给定实体s的可能对象;或不返回对象,表示有没有给定实体s和关系的三元组。
在这个框架下,三重提取是一个两步过程:
1.我们识别一个句子中所有可能的实体s;
2.对于每个实体s,我们应用关系特定的标记器来同时识别所有可能的关系和相应的对象。
CASREL框架将实现上述步骤。它由一个BERT 模块、一个subject标记模块和一个特定于关系的object标记模块组成。
公式推导
到了头疼的公式推导环节,非战斗人员请撤离
给定注释的句子 xj 从训练集 D 和一组可能重叠的xj 中的三元组 Tj = {(s, r, o)} :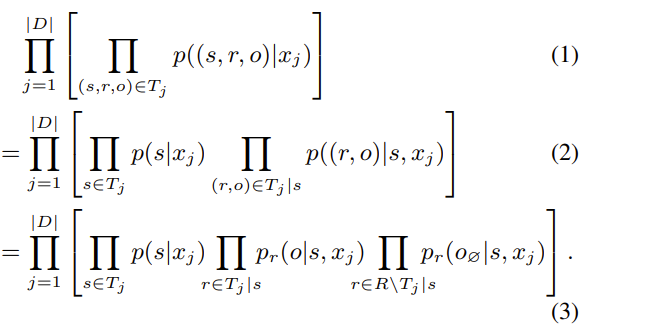
第二步应用了概率的链式法则方程。第三步,我们应该承认:对于一个给定的主题 s,与 s 相关的任何关系(Tj |s 中的那些)会导致句子中出现对应的宾语,并且所有其他关系必然没有句子中的宾语,即“空”宾语。
我们的目的是把公式(3)的每一块尽量提高,以保证最后结果最大。(即最大化训练集 D 的数据似然度)
模型框架
事实上,这种新颖的标记方案使我们能够一次提取多个三元组:我们首先运行subject标记器以查找句子中所有可能的subject,然后对于找到的每个subject,应用特定于关系的object标记器以查找所有相关的关系和对应的object。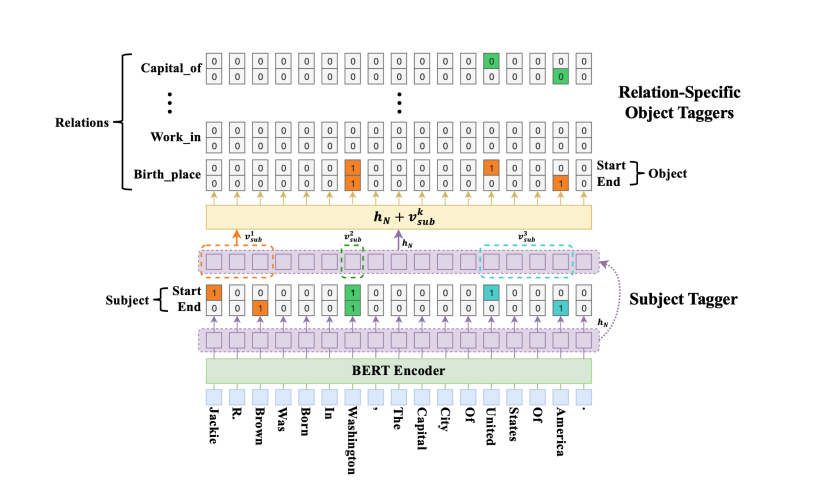
An overview of the proposed CASREL framework. In this example, there are three candidate subjects detected at the low level, while the presented 0/1 tags at high level are specific to the first subject Jackie R. Brown, i.e., a snapshot of the iteration state when k = 1 is shown as above. For the subsequent iterations (k = 2, 3), the results at high level will change, reflecting different triples detected. For instance, when k = 2, the high-level orange (green) blocks will change to 0 (1), respectively, reflecting the relational triple (Washington, Capital of,United States Of America) led by the second candidate subject Washington.
BERT ENCODER
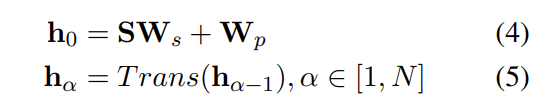
其中 S 是输入句子中子词索引的 one-hot 向量矩阵,Ws 是子词嵌入矩阵,Wp是位置嵌入矩阵,其中 p 表示位置输入序列中的索引,hα是隐藏状态
向量,即输入句子在第α层的上下文表示,N是Transformer块的数量。
输入:单个文本句子输出:综合文本信息的单词向量矩阵
Cascade Decoder
首先,我们从输入句子中检测主体s。 然后对于每个候选主体s,我们检查所有可能的关系,看看是否有关系可以将句子中的对象与该主体s相关联。
这又分为两个模块
1.Subject Tagger
通过直接解码 N 层 BERT 编码器产生的编码向量 hN 来识别输入句子中所有可能的主体。
它采用两个相同的二元分类器来检测对象的开始和结束位置,如果概率超过某个特定阈值,则标记为 1,否则标签 0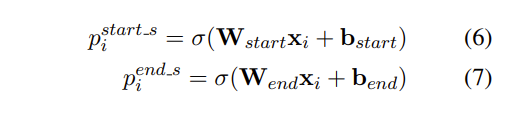
W是训练权重,xi=hn[i],b是偏差,derta是激活函数
此外论文中还提到了实体跨度的监测,在此不再赘述
2.Relation-specific Object Taggers
所有对象标记器object taggers将同时为每个检测到的对象识别相应的对象。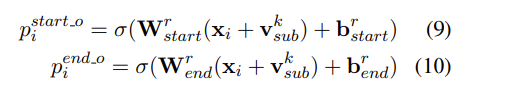
参考论文
A Novel Cascade Binary Tagging Framework for Relational Triple Extraction