AESINER模型分析
NER 的主要方法传统上被认为是具有隐马尔可夫模型 (HMM) 和条件随机场 (CRF) 等模型的序列标记任务学习。而神经模型也占据主导地位。原因是他们在编码上下文信息方面非常强大,可以驱动 NER 系统更好地理解文本并识别输入文本中的NE。
对于一段语料而言,有很多句法特征,例如词性标签、句法成分、依赖关系等。对NER任务来讲,这些特征可以有效地识别一段文本中的继承结构,从而指导系统相应地找到合适的实体单元。因此,寻找合适的方法将这些信息整合到神经模型中,将会是一次全新的突破。
AESINER提出了一个巧妙的解决方案。
有监督 or 无监督?
AESI模型是有监督学习。其预训练的嵌入包含从大规模语料库中学习到的上下文信息,在本模型中通过在输入中直接连接多个预训练嵌入来合并它们,这里的预训练都是给出训练文本对应标注的训练,因此判断为有监督。
数据集样式
输入:普通文本中间输出:每个词向量的句法信息(包括词性标签、语法信息和依赖关系)的集合最终输出:输出句子中判断出的实体标签
输入:Today is my last day at my office.
1 | |
最终输出:
today O
is O
my O
last O
day O
at O
the O
office O
. O
模型框架
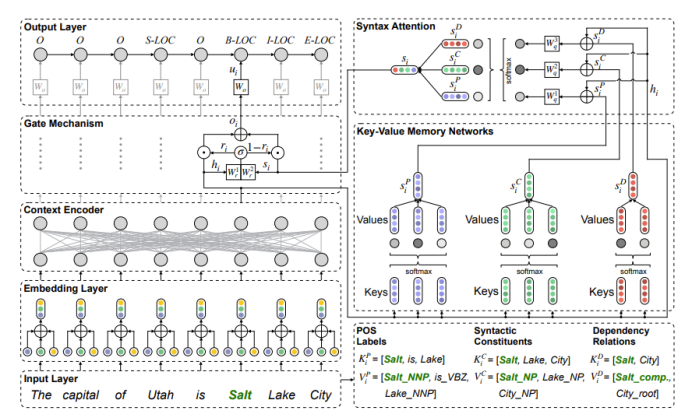
AESINER由6个模块组成。
1.Embedding Layer & Encoder
以transformer作为上下文编码器,输出单字在句子中的向量表示输入:文本输出:文本中各个字融合了全文语义信息后的向量表示
2.句法信息提取
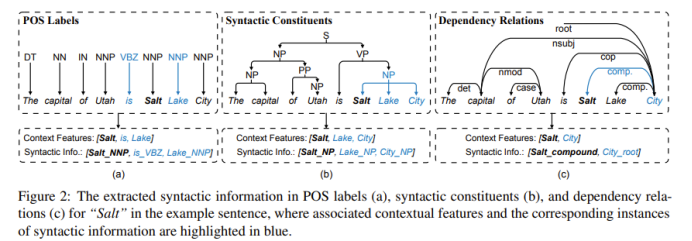
For POS LABELS:我们将每个 xi 视为中心字并采用±1字的窗口来提取
它的上下文词及其对应的词性标签。
例如,在图 (a) 的示例中,对于“Salt”,±1 字窗口覆盖其左侧和右侧的单词,以便生成的上下文特征是“Salt”、“is”和“Lake”,我们使用这些词及其词性标签的组合作为POS 信息(即“Salt NNP”、“is BVZ”和“Lake NNP”)用于 NER 任务。
For syntactic constituents:我们从 xi 开始(X 的语法树的叶子),然后向上搜索树来找到第一个可接受的语法节点2,并选择该节点下的所有标记作为上下文特征,并将它们组合起来用语法节点2获取成分信息。
例如,在图 (b) 中,我们从“Salt”开始并提取其第一个接受节点“NP”,然后收集“NP”下的token作为上下文特征(即“Salt”、“Lake”和“City”)并将它们组合起来
用“NP”来获取成分信息(即,“Salt NP”, “Lake NP”, and “City NP”)。
For dependency relations:对于依赖关系,我们找到所有上下文,通过收集其所有依赖项来为每个 xi 提供特征。然后考虑上下文特征的组合和它们的入站依赖类型作为相应的依赖信息。(不说人话是吧,直接看例子)
例如,如图 (c) 所示,对于“Salt”,其上下文特征是“Salt”和“City”,以及它们对应的依赖信息是“Salt compound”和“City root”.
输入:字向量输出:每个字对应的POS LABELS、syntactic constituents、dependency relations的key-values向量表示
3.kvmn模块
由于句法信息是从现成的工具包,可能有提取的句法信息中的噪声,其中如果使用不当,可能会损害模型性能。此模型提出了一个 KVMN 模块(Mc)对成对组织的上下文特征进行建模和句法信息实例。
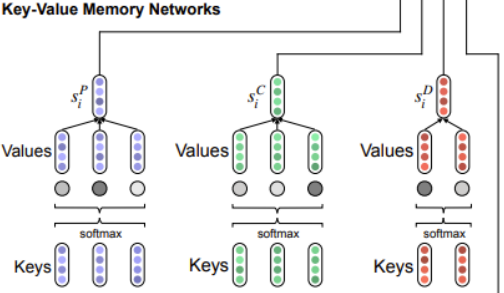
首先映射它的上下文特征和句法信息到 KVMN 中的键和值,用Kc i = [k c i,1 , . . . , kc i,j , . . . , kc i,mi ]和V c i = [v c i,1 , . . . , vc i,j , . . . , vc i,mi ]表示
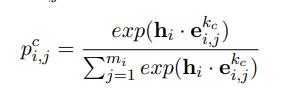
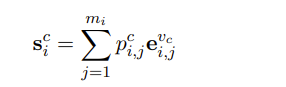
Si是Mc(即KVMN模块)的输出
KVMN 保证了句法信息根据其对应的上下文特征进行加权,以便重要信息可以相应地加以区分和利用
输入:每个字对应的POS LABELS、syntactic constituents、dependency relations的key-values向量输出:由k-v映射出的si向量
4.The Syntax Attention
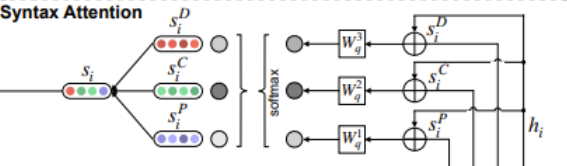
在对每种类型的句法信息进行编码时通过 KVMN,最直接的做法是把他们直接相连。然而考虑到不同的句法信息可能会相互冲突,所以采用一个更有效的方式将它们结合起来。
输入:si向量输出:si‘是不同句法类型的syntax attention的输出
5.The Gate Mechanism
AESI模型提出了一种门机制 (GM) 将其合并到主干 NER 模型中,其中这种机制可以动态加权并决定如何在标记 NE 时利用句法信息。
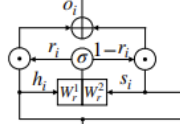
主要操作是重置函数ri得到来自上下文编码器的编码和语法注意
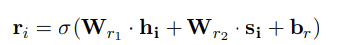
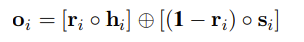
输入:si‘和hi(融合了全文语义信息后的字向量表示)输出:Oi(对应于输入xi的门机制输出)
6.Output layer
将oi用一个可训练的矩阵 Wo 用于将其维度对齐到ui = Wo · oi 的输出空间得到yi。之后应用条件随机场 (CRF) 解码器预测标签 y^i ∈ T(其中 T 是具有所有NE标签),再输出序列Y
输入:oi输出:最终的标签序列Y
参考论文
Improving Named Entity Recognition with
Attentive Ensemble of Syntactic Information