基于TABLE FILLING的NER&RE
在以往的NER&RE的任务中,很多方法都是基于复杂的手工特征和神经网络架构,这导致训练的时间和基于历史的预测时间较长。
现在呢,有大佬提出了一种新颖而简单的方法:基于表格表示从非结构化文本中提取命名实体和关系
输入:单词序列w1,w2 ... wn(n 是输入中的单词数)
Johanson Smith lives in London
输出:关系三元组(arg0type0,relation,arg1type1)
(Johanson_B-PER,LiveIn,London_U-LOC)
(Smith_B-PER,LiveIn,London_U-LOC)
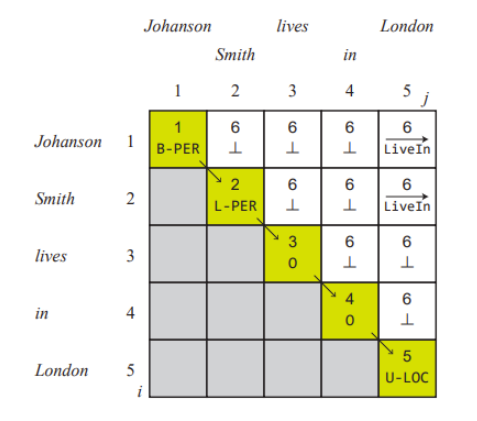
具体怎么整呢。我们定义一个 n×n 上三角矩阵 Y ,其中对角元素 Yi,i ∈ E (1 ≤ i ≤ n) 表示词wi,非对角元素 Yi,j ∈ R(1 ≤ i < j ≤ n) 表示有向关系单词 wi 和 wj 之间的**标签。
此模型可以看做将一系列单词 w1w,2 · · · wn映射到上三角矩阵
模型框架
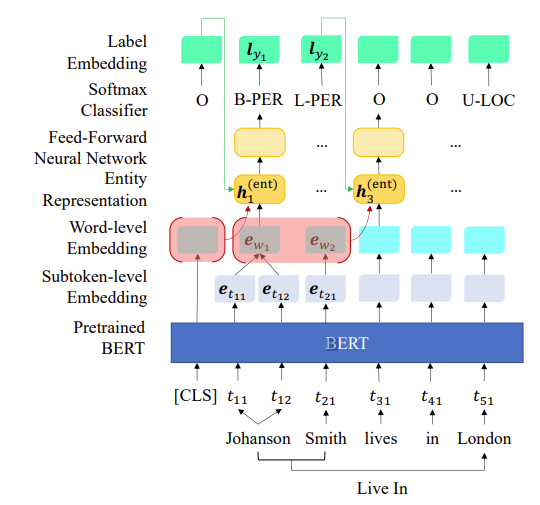
该模型分为并行的两块,在到达Entity Representation层后,分别用不同的方法进行ner和re。也就是说,我们在 BERT 编码器之上执行 RE
识别实体之后,NER 模型填充 Y 中的所有对角线元素,RE 模型预测所有非对角元素。
Named Entity Recognition
BERT
BERT 分词器使用 WordPiece 拆分单词在 BPE 的帮助下转化为子词标记
“Johanson” –> “Johan”和”##son”
输入:经WordPiece处理过的子词序列输出:文本中各个子词融合了全文语义信息后的向量表示
Word-level Embedding
由于 NE 是在单词级别注释的,我们在训练和预测两个过程中都需要它在单词级别的表示。
计算方法如下:
Bert嵌入的子词标记组成词(eti,1,eti,2…eti,s)作为输入,ewi作为输出
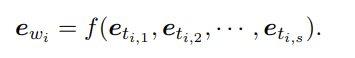
f表示一个最大池化操作,即对(eti,1,eti,2…eti,s)进行降维压缩,以某种方式取最大值
输入:子词向量输出:池化后的word level的单词向量
Entity Representation
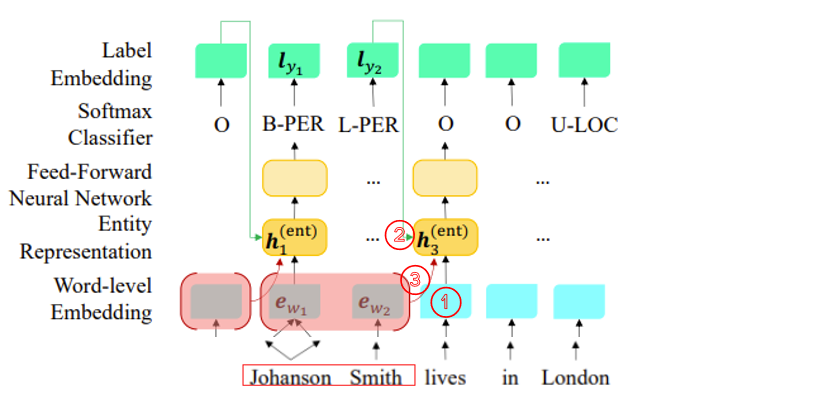
计算方法如下:
①词wi的表示ewi
②上一个标签yi-1的embedding lyi−1
③出现在时间步长上的前一个 NE 跨度的 BERT 嵌入的最大池化(翻译成人话:上一个实体的向量表示)
如上图的示例,③为上一个实体”Johanson Smith”的向量表示
其中⊕代表向量连接。
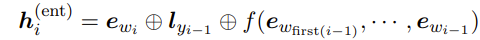
输入:①⊕②⊕③
输出:关系隐藏向量h
Softmax Classifier of NER
之后应用一个全连接层,然后是一个softmax 函数 σ 在时间步 i 处获得所有可能的 NE 标签的概率分布,之后选择概率最高的y^i填充Yi,i (= yi)
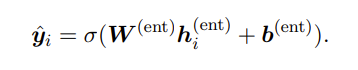
输入:关系隐藏向量h、矩阵w、线性变换的偏置向量b输出:概率最高的标签y
Relation Extraction
RE模型利用实体跨度和他们的NE标签以获得关系表示,用于预测关系标签。
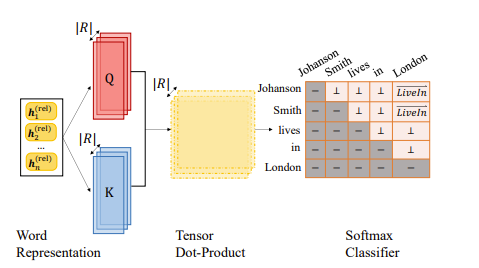
Word Representation
实体跨度特征 zi(在时间点 i)是使用实体跨度中组成词的表示来计算的:
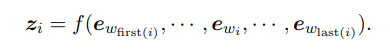
换个说法,zi是从 first(i) 开始的,last(i)结束的实体跨度的单词表示的最大池化。
在数学上,单词表示,即 RE 模型的输入,是实体跨度和实体标签特征的串联,
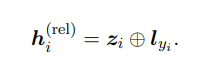
生成qk矩阵张量
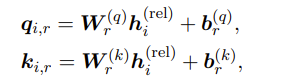
输入:实体跨度zi和实体标签特征lyi的串联输出:qk矩阵张量
Tensor Dot-Product
输入:qk矩阵张量输出:qk张量的点积
Softmax Classifier of RE
Softmax 函数σ 计算所有的概率分布关系标签 R。我们用产生最高概率的关系标签记为y^i,j 。
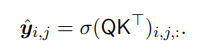
输入:qk张量的点积输出:产生最高概率的关系标签y^i,j